Introduction
Automated systems powered by deep learning have been taking the world by storm. However, deep neural networks are notoriously black boxes, and no one truly understands how they make specific decisions. As these decisions become increasingly high-stakes, it's easy to see why interest in the interpretability of deep learning models has been steadily increasing.
For example, consider the case of medical diagnosis, where AI-generated diagnoses have started to outperform medical experts in accuracy. If the AI's diagnosis differs from the human's, but the system is unable to provide an explanation, can doctors and patients really trust the model?
Similarly, what if an autonomous vehicle makes a drastic misclassification, which leads to a fatal accident? How can engineers fix the issue if they don't even understand what caused the AI's error in the first place?
Unfortunately, it's surprisingly difficult to nail down what 'interpretability' actually means, as it relates to a human's understanding rather than just cold, hard numbers. Even after years of research, there is still no single agreed-upon definition of what we mean by an interpretable model. However, this hasn't stopped hundreds of papers from claiming to have improved interpretability (and I have been guilty of this too), without being precise in their specific definition.
As it turns out, when you don't fully specify why exactly you want your model to be interpretable, it's very easy to fool yourself about what you have really achieved. So rather than give a comprehensive list of definitions and delineations, of techniques and taxonomies, of methods and metrics, I want to tell 3 stories about when interpretability didn't live up to its promise.
Saliency Maps
So let's look at an example of how researchers have approached interpretability. One popular family of methods are so-called 'Saliency Maps'. Essentially, when an AI model identifies an image, we want it to be able to highlight the most important parts of the image that led to its decision. This helps us understand whether the model has learned to recognize the correct features or is focusing on irrelevant details.
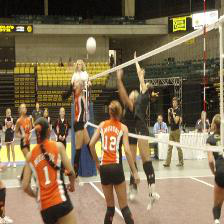
For instance, consider the image above taken from the well-known ImageNet dataset that involves classifying images into 1000 different categories. Any decent ImageNet classifier would quickly identify this as a volleyball. But to understand why the model made this prediction, we can use a commonly used technique called Integrated Gradients to generate a saliency map. This technique highlights the most relevant parts of the image that contributed to the classifier's decision. The details of how Integrated Gradients works aren't important here, but the resulting saliency map provides us with a clearer picture of why the model made its prediction.

Aha! It seems like the model is not only paying attention to the volleyball, but it also keeps an eye out for the net and the numbers on the player's jerseys. While it's understandable for a classifier to learn these features, they might not be the most important ones for correctly identifying a volleyball. This is where interpretability comes in handy - by using saliency maps, we can get a better sense of what features the model is focusing on and make sure it's learning the right ones.
Or how about the next example, where the model correctly recognizes the snow leopard but somehow only thinks the hind paw mattered for that decision. Maybe it's because the rest of the body is in the shade and thus not white enough? It seems like we are really learning something about our model's inner working here.


Except... I lied! The saliency maps I just showed were actually generated on a completely untrained model, that has literally never seen a single image and certainly wouldn't know the difference between a volleyball and a snow leopard. But if we put these untrained saliency maps next to the ones from the trained model, we see that we could have easily drawn the same conclusions from the true saliency maps.


So have we learned anything from the interpretability tool about how our model works? Probably not. That doesn't necessarily mean that this particular interpretability method never works but it should definitely serve as a cautionary tale, not to jump to conclusions. Clearly, nodding along with visualizations that seem to make sense is not good enough for evaluating interpretability methods.
Lesson Learned: Even a reasonable-looking interpretability technique can fail basic sanity checks.
Understanding Individual Neurons
Okay, so instead of just generating cool visualizations and calling it a day, we should make sure that our interpretability method at the very least passes some basic sanity checks. But really, we want more than that. We want to know that our interpretability method actually has some measurable utility for potential users. How can we measure if some visualization has actually aided a user's understanding?
Let's look at the example of Feature Visualizations. It's a method that is supposed to help researchers understand specific neurons in an artificial neural network. Remember that neural networks consist of many layers of artificial neurons. Lower layers feed their outputs to the higher layers and so on. Conventional wisdom in AI says that in the lower layers the network recognize simple structures like lines and shapes and at higher layers it starts encoding more complex concepts like houses or cars. Can we find a way to understand what an individual neuron actually does in a network?
Here is an idea: what if we start looking for images that make the neuron really excited? In fact, we can use mathematical optimization techniques to artificially generate images such that our chosen neuron starts being super active. Below you can see what these artificially generated images look like. What's really cool about this is that these images tend to capture concepts that humans are sort of vaguely able to recognize.



Visualizations copied from the original publication.
This looks cool and all, but let's not jump to conclusions. With our skeptical hats on we wonder if this actually improves people's understanding of what a neuron encodes. In order to test this, we can run the following experiment: we show someone a bunch of images that are super exciting for our chosen neuron. At the same time we can also show images that are extremely boring to the specific neuron, i.e. images that lead to the least activation. Now we show the user two new images and we ask them which image will likely produce the stronger response in the given neuron.

As you might guess, the car image excites the current neuron more than the dog image. We can sort of infer this from the spoke-like patterns on the right. Visualizations copied from this paper.
So if you actually run this experiment, you find out that... the method works! People are able to correctly guess the right image 82% of the time. Not bad! Remember that random guessing would only lead to 50% performance. So if the users are demonstrably able to kind of predict how the neuron would behave on future inputs, then they must have understood something about it, right?
Then what's the problem? The problem is that we actually could have gotten even better performance using a way simpler method. If instead of going through all the hassle and expensive computations needed to generate the artificial images, we can instead just throw a whole bunch of natural images at the model. We then see which ones of those excite the neuron the most and show those images to the users. Turns out if you do that, the users' performance climbs to a staggering 92%.
Lesson Learned: Even if your fancy method works, a trivial baseline might work even better.
From Dev to Prod
At this point we have learned to be very suspicious of explainability methods. But let's say we come up with a method that passes all sanity checks, and then we evaluate it and we prove that it can actually aid a user's understanding of the model, and then we even show that the method does a better job at this than trivial baseline methods. Surely, then we can start handing this out to real machine learning practicioners and congratulate ourselves for having made the world of AI just a little more trustworthy.
Of course, you know what I am going to say next. Even now, things could still go wrong because even a good method can simply be applied incorrectly by practitioners in their day-to-day work.
A study tried to investigate this and indeed found some pretty troubling results. They gave real data scientists who were working in industry some machine learning model along with interpretability tools to see how the industry experts would use them. Because a lot of machine learning in industry is working on exciting stuff like financial spreadsheets, this study didn't focus on vision models but on a model that would take tabular data about a person (marriage status, age, ethnicity etc.) and predict if they made more or less than $50.000/year. Of course sneaky as always, the designers of the study had also purposefully inserted some gotchas into the data. For example, they simply replaced 10% of all people's ages by the mean value 38 because they knew that this would trip up the models they trained on this. Would the user's be able to catch these problems using the interpretability tools? Would they even correctly understand what the visualizations were telling them?
According to the study's results... not really. Apparently, people were quite happy using the tools to construct narratives around model predictions, even if they hardly even understood what they were seeing. For example, take the following quote from one of the participants:
"The charts in combination help you infer reasonable things about the model. Person has college level education, working in private sector full-time, having married to civilian spouse and white race indicates high income which makes actual sense."
Apparently, this user was fully on board with the model explanation. The problem is, this participant had actually been shown manipulated explanations that highlighted the opposite of what the model was paying attention to. In fact, there was no signifcant difference in how reasonable the users found the real explanations and the manipulated ones. At least the manipulated explanations led to users finding the models themselves slightly less reasonable but nonetheless, their willingness to deploy these models remained basically unaffected.
Let's not forget these were not random people off the street. They were machine learning professionals at large companies who had specifically been given instructions on how to interpret the interpretability tools. Ultimately, it seems the users' expectations of the interpretability methods were sometimes more important than the methods themselves. The users knew that they were using well-known methods from publically available tools so they just assumed that the methods were reasonable. But as we learned today, that's really not a safe assumption to make.
Lesson Learned: No matter how good your method, users might misuse it.
Conclusion
Interpretability is all the rage in the discourse about trustworthy machine learning. That makes it all the more important to know some of the pitfalls that can happen in interpretability. First of all, a method might not even pass basic sanity checks. Even if it does, it might not truly improve a user's performance on anything tangible. But even if it does that, then a much simpler baseline might still do an even better job. And even after ruling out all of these issues, users in practice might misunderstand and misuse the technique.
Also notice that in each of these cases, the papers that originally proposed some hip new method have countless times more citations than the papers that pointed out their flaws. And all of this in a world where we are steadily handing over more responsibility to these black-box algorithms. Clearly, the nascent field of interpretability still has a long way to go before it can truly help us to make machine learning safe and reliable.